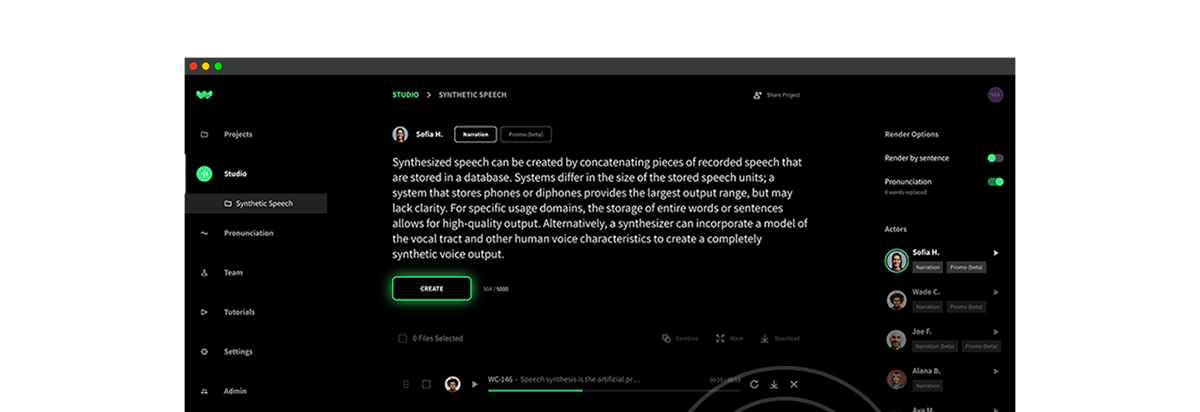
Most AI voice providers use a similar strategy for creating a voice avatar from voice actor recordings. At WellSaid, we have updated our Voice Model to use an entirely different type of machine learning. That means that our newest Voice Model powers the most lifelike, natural sounding voice avatars available.
Read on to learn how this experience changes voiceover production for our Studio customers.
Why update the Voice Model?
In the past, the WellSaid Voice Model would read many common abbreviations, dates, currency formats, and acronyms in the most literal sense. The model was unable to read any context to content and would sometimes need adjustments to say something like, “March 5th, 2021” correctly.
Read more specifics about the update here.
With the new update, you can render these types of expressions accurately on the first try. Rather than listing individual letters and numbers, as a more primitive AI voice model will, the new WellSaid Model can read the characters in context.

Here are a few more examples of language that the new model accommodates:
- Money ($1, $1.00, $10M, etc)
- Ordinals (1st, 2nd, 10th, 30th, etc)
- Times (10:34 am, 10PM, etc)
- Phone Numbers ((890) 345-1234, 1-888-CALL-NOW, etc)
- Years (1998, 2020, 80s, c. 300 BC, etc)
- Number Ranges (1-3 as ‘one to three’, etc)
- Percents, Number Signs (12.3% as ‘twelve point three percent’, #1, #2 as ‘number 1, number 2’, etc)
- URLs (wellsaidlabs.com, https://www.myurl.com/reference, name@company.com, etc)
- Acronyms (NASA, OPEC, etc)
- Abbreviations: Measurements (1 ft., 2 in., 4 oz. etc), Titles (Mr. as ‘Mister’, ‘Sr.’ as ‘Senior’, etc), Others (St. for street, Apt.` for apartment, etc. as etcetera, etc)
- Generic Numbers and Symbols (1,234, &, /, etc.)
This updated model makes creating voiceover more accurate, easier, and faster, too.
More Pronunciation and Emphasis Assistance
For the most difficult phrases and words, WellSaid Studio customers have gained value from using the Pronunciation Library to save commonly used vernacular.
Studio now has an even more powerful pronunciation tool: Respelling. Some AI voice providers ask customers to learn the complicated and archaic International Phonetic Alphabet of symbols to specify pronunciation.
WellSaid went a different direction.
Now, content creators have a Respelling catalog of English sound combinations to use that is approachable and intuitive.
In short, Respelling is a way to combine syllables and specify the emphasis of a word to get it exactly right. It’s especially helpful for proper nouns and scientific terms that have complicated pronunciation.
Most words will be spelled correctly without using Respelling, but it is available if you need. You can also continue using shortcuts from your Pronunciation Library, and add Respelling to your library.
Read more about Respelling in our Knowledge Base article.
A Voice Model That Reads Like a Voice Actor
At WellSaid Labs, we strive to always improve our Voice Model to make it more lifelike and easier to use. With every update, you can render more accurate text to speech with fewer adjustments.
Want to learn more about our Voice Model update? Register for our free webinar on August 25 at 3PM ET.

Not a WellSaid Studio customer? Start a no-commitment free trial to hear our AI voices for yourself!