
Audio by Hannah A. using WellSaid Labs This post is from the WellSaid Research team, exploring breakthroughs and thought leadership within audio foundation model technology. In an era where digital
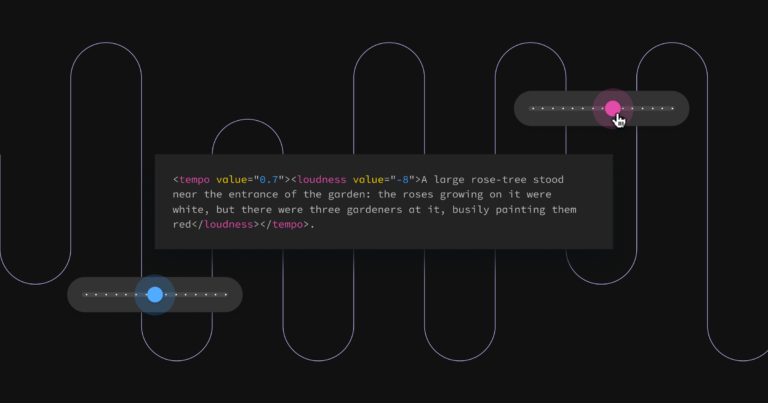
Crafting authentic vocal performances via interpolable in-context cues Audio by Paige L. using WellSaid Labs This post is from the WellSaid Research team, exploring breakthroughs and thought leadership within audio
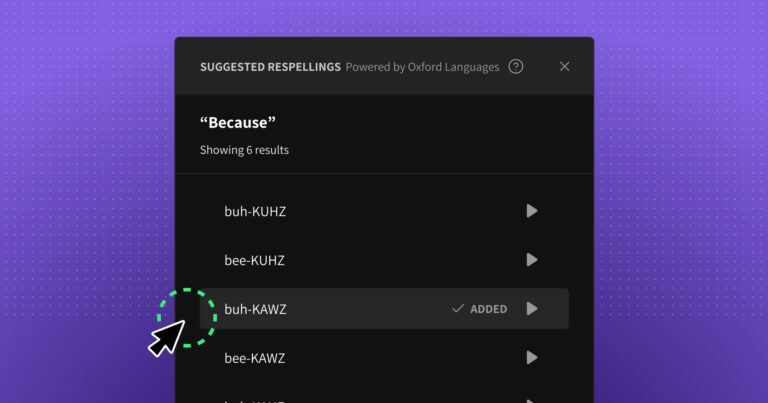
Audio by Joe F. using WellSaid Labs The State of AI Pronunciation Among the countless AI-driven innovations, text-to-speech (TTS) technology is a versatile tool that revolutionizes how we interact with

Audio by Owen C. using WellSaid Labs This post is from the WellSaid Research team, exploring breakthroughs and thought leadership within audio foundation model technology. No one sums up the

Audio by Tilda C. using WellSaid Labs This post is from the WellSaid Research team, exploring breakthroughs and thought leadership within audio foundation model technology. The prospect of machines mimicking

Audio by Paula R. using WellSaid Labs Ever watched a movie without its score? Or imagined a game without its defining sound effects? Audio is an unsung hero, subtly crafting
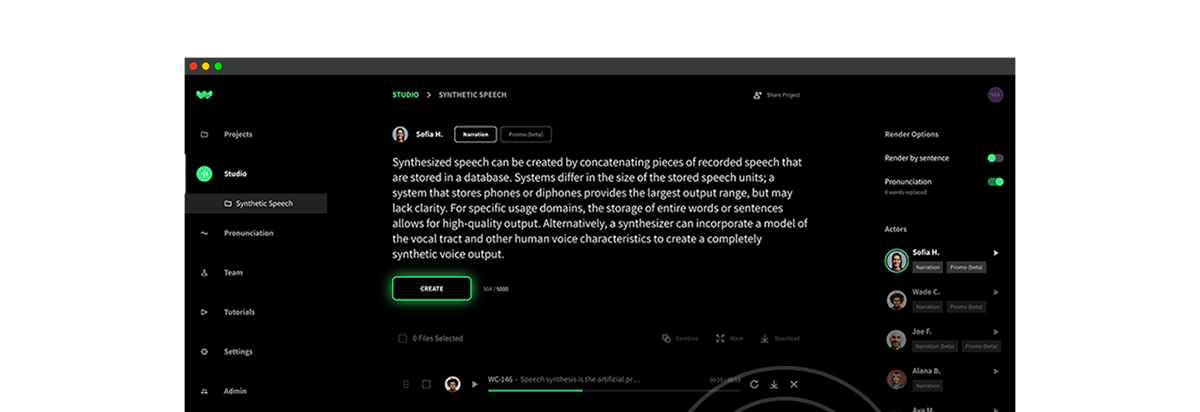
© WellSaid, Inc. 2024
All rights reserved.
