If you’re looking for the best text-to-speech API available, you’ve probably heard some REALLY bad AI voices. In the past, synthetic voice technology delivered robotic, rigid, and sometimes comical sounding voices. Unfortunately, this limited the ability to use artificial voice that would be a net positive to the user experience.
As advancements usher in more AI-powered solutions, anticipate an auditory shift. Why? Because engaging through sound complements, and often even surpasses, visual-only interactions. The era of the AI voice represents much more than a playground of tech behemoths. From app developers to content creators, synthetic voice has become the key to enriching user engagement, bolstering retention, and crafting experiences that resonate.
In truth, a captivating voice can be transformative. It anchors brand familiarity, amplifies accessibility, and streamlines onboarding. But herein lies the challenge: How do organizations amplify voice to a degree where authenticity is undebatable? The bygone days of robotic, lackluster synthetic voices limited brands. Now, with AI propelling synthetic voice ever closer to human-like inflection, brands are revitalizing their voice infrastructure. They’re enhancing customer service, converting verbose articles to audio, and sculpting immersive app experiences.
In this guide, we’ll be diving into synthetic voice API use cases, showcasing the might of scaled AI voice and how your organization can capture the momentum.

What is an AI Voice API?
Starting with the basics, it’s well-worth discerning what an AI Voice API is—and what it isn’t. An AI Voice API is a unified interface, streamlining the conversion of text to audio via AI Voices from diverse providers. Benefits are wide-ranging and plentiful, from seamless integration, automatic updates, and, paramount of all, scalability.
Now, make sure to avoid muddling this AI Voice API and voice APIs. Sure, they might sound like potato-potato. But, on the contrary, a basic voice API is a developer tool for making and receiving calls.
How Are Voices Created?
In order to deliver truly lifelike AI voices, a lot has to happen behind the scenes. However, typically, the process broadly looks like this.
Text Processing: Voice generators phonetically and linguistically interpret written text.
Linguistic Modeling: Next, linguistic rules shape the voice’s pronunciation, emphasis, and tone.
Acoustic Modeling: Linguistic features morph into human speech patterns.
Prosody Modeling: Techniques such as pitch, inflection, and speed are fine-tuned for naturalness.
Waveform Generation: The finale—acoustic patterns produce a fluid audio waveform.
Working in tandem, these models birth coherent spoken outputs, making AI voice apt for reminders, support, music, and more.
Considerations of AI Voice Integrations
As a result of a jump in voice quality, organizations of all sizes are scaling up their voice infrastructure. Additionally, they are also improving customer service interfaces by adding vocal audio. Some are converting long form articles to voice. Still others are creating immersive app experiences that incorporate a realistic human voice.
Learn more: Download our free API Use Case Ebook
How Synthetic Voice is Used
Artificial intelligence powers a spectrum of language processing tools. Let’s delineate the types of synthetic voice technologies and their applications.
Text to Voice: This encompasses converting text to speech, be it for narrating long articles or embedding voice instructions in wellness apps.
Voice to Text: Contrary to Text to Voice, this involves transcribing vocal input into text. For instance, turning sales conversations into searchable text snippets in tools like Gong.io.
For this discourse, our spotlight is on Text-to-Speech (TTS)—or “Text-to-Voice” technology. For a broader perspective on language processing apps, the Sequoia Capital map of “Generative AI” is a treasure trove.
Not All Text-to-Speech APIs Are Equal
Speed, cost and quality are typically the three main criteria used when evaluating a text-to-speech API. However, for some organizations, a semi-robotic voice is sufficient, if the price is right. Other times, developers just need a voice to fill in while their application is being built. They’re still proving their use case. Eventually, WellSaid’s API is chosen over other alternatives because voice quality is paramount.
Alternatives to Google, Amazon and Microsoft Text-to-Speech APIs
Tech giants like Google, Amazon and Microsoft are comparable to a McDonalds cheeseburger. How? Glad you asked! They’re readily available, affordable and offer adequate satisfaction. API customers choose WellSaid API because the quality of voice is paramount for the success of their voice application. They need “Michelin star” synthetic voice.
The Secret About Some Text-to-Speech APIs
Unless you’re an industry insider you’d never know this little secret. Many of the companies that WellSaid is compared to are white labeling the APIs from tech giants. They simply re-brand the voices. They have no proprietary language AI. WellSaid CTO, Michael Petrochuk, innovated the WellSaid voice model himself. That is why the quality of WellSaid voices leads the industry and outshines the voices available from tech giants.

Our AI Voice Research and Results
Creating natural-sounding speech from text is one of the grand challenges in the field of AI. It has been a research goal for decades. Over the years, WellSaid Labs has consistently researched and developed tremendous breakthroughs in the quality of text-to-speech systems.
One way to evaluate the quality of AI voice avatars is to survey listeners on how natural a voice sounds. Listeners ranked voice samples on a scale of 1 (Bad: Completely unnatural speech) to 5 (Excellent: Completely natural speech).
Participants in the study then listen to a mix of voice actors recordings and clips from WellSaid AI Voice Avatars. Shockingly, participants ranked the voice actor clips at a 4.5, and ranked WellSaid avatar clips at 4.2. These findings were then audited by a third party research company for accuracy. In the end, WSL became the first company to achieve human parity, and to this day is a market leader.
Want to hear the best AI Voices for yourself? Try all our Voice Avatars for free!
The Best Text-to-Speech API
There are a wide variety of text to speech APIs with different applications. Here is a list of some of the most commonly used text-to-speech APIs.
- WellSaid API is the best text-to-speech API for quality of voice. A unique sound, including breaths and pauses, emulates the human voices used to train the AI voice model. This naturalness is the reason WellSaid voices can be found across so many industries and applications.
- Synthesia.io – offers an API for going from text (a script) to a video of an AI avatar. This API is in beta.
- Play.ht – offers a TTS API that simplifies accessing a wide variety of voices from IBM, Microsoft, Google and Amazon AI voice libraries.
- Listnr.tech – offers an API that specializes as a text reader that converts articles to narrations in multiple languages.
- Descript.com – offers a text to speech API geared toward content creators and marketers that want to quickly generate content assets such as podcasts, video, transcriptions and screen recordings.
- Google, Amazon, and Microsoft – offer text-to-speech APIs best suited for value, each also offer a large variety of languages making it ideal for worldwide applications.
- Speechify.com – offers a TTS API with a focus on rendering articles into audiobooks for elearning at all ages.
How Text to Speech APIs Are Used at WellSaid Labs
The AI voice revolution is not limited to billion dollar tech companies. App developers and content creators of all kinds are turning to synthetic voice. Why? To increase engagement with products, improve retention, and create innovative experiences that delight users.

A compelling voice is an incredible catalyst for increasing engagement with your product and building brand loyalty. However, the challenge organizations face is scaling up voice so that it sounds genuine and realistic.
App and Product Experience
The experience we derive from apps and products is continuously evolving. A vital component of this evolution is the incorporation of high-quality synthetic voice. No, this isn’t a run-of-the-mill text-to-speech API, but a Generative AI voice API. When integrated effectively, it profoundly enhances the user experience across multiple platforms.
One significant benefit? Information retention. Leveraging both visual and auditory senses, users can better grasp and remember messaging. When text is complemented with video, an impressive 95% of the message is retained by users. In contrast, relying on text alone holds a meager retention rate of 10%.

Lifestyle Apps
PEAR Health Labs uses AI to create “personal adaptive coaching” for a variety of wellness apps. These applications range from supporting fitness wearables apps to training intelligence apps for military and first responders. PEAR customers use their proprietary AI to build training plans. Meanwhile, AI voice provides a consistent, branded delivery option for delivering information. With this technology, wellness app creators and instructors can scale their personal training across locations and platforms.
Educational Apps
This category covers a wide range of informative apps, but one of the biggest segments is educational content for children. The Explanation Company seeks to “build the internet for children,” with search functionality built for early readers. Using synthetic voice, the app can interact with young learners who don’t have the literacy skills to use traditional search engines. Then, it can answer questions with conversational AI, rather than text alone, engaging a whole new generation of app users.
Informational Apps
An exciting new way to consume content across the digital world is with apps like Uptime. Interestingly, this service can aggregate material from numerous sources. Uptime “packs thousands of life lessons extracted from best books, courses, documentaries, and podcasts into 5 minute Knowledge Hacks.” The average time in-app for Uptime is 10 minutes. They also boast an 11% click-through rate on each “Knowledge Hack.” By providing a variety of consumption options, including AI voice, apps like Uptime are finding ways to appeal to a broader user base.
Programmatic Content Creation
Harnessing AI for content creation, especially voice content, will elevate your content—and, importantly, make your life a whole lot easier. Consider this: tasks that previously demanded extensive hours in recording studios can now be executed in mere minutes using text to voice API. From streaming to customer interfaces, to the rise of audiobook creation—the applications are manifold.
Radio Streaming
Outside of audio advertising, Generative AI is changing the way audio streaming is done. Companies like Super Hi-Fi are using synthetic voice to integrate with branded audio content. By using AI-powered automations, now Super Hi-Fi can help terrestrial and satellite radio stations and streams create more immersive experiences. These improved experiences drive engagement and brand loyalty. Check out the AI voice radio DJ that Super Hi-Fi created.
Customer Interface
Conversational AI gives you a new competitive edge. How does that help customer interfaces? By enabling proactive communication and automated support at any stage of the customer journey. Curious Thing helps companies use artificial intelligence to provide custom content. This material is relevant to their needs and questions at that exact moment. The Curious Thing tech improves the experience for the customer. They now get the information they need at exactly the right time. It also helps the company scale without additional support headcount.

Check out a replay recording of this session on WellSaid API
Audiobook Creation
Synthetic voice has the ability to enable widespread audiobook creation, especially with products like Speechki. Using AI voice and simple editing tools, the Speechki platform can create an audiobook in just 15 minutes. Unlike conventional audiobook recording, this process is cost-effective for academic journals and independent publishers. Audiobook platforms like Speechki drastically increase the amount of audio content available for listeners.
Sales and Marketing
One of the ways that AI voice is revolutionizing voiceover is with the ability to create infinite variations of content. With unique, listener-centric voiceover, brands can tailor a message to a specific audience. The application of this is obvious for audio advertising, but it extends to other exciting marketing uses. Custom video and video avatars are also taking the AI marketing space by storm.
Audio Advertising
Artificial intelligence is changing every aspect of audio advertising- targeting, bidding, and content creation. Companies like Decibel Ads are focused on helping brands create bespoke ads, quickly and easily. With what they call “listener-level targeting” and synthetic voice, Decibel customers can create and test multiple versions of ads. More importantly, this just takes a few minutes.
Personalized Video
When a customer hits a roadblock using a product or has a question about an invoice, SundaySky empowers companies to create videos just for that customer. With bespoke content made in real-time, the video is personalized with their name, account details, and more. Not only do SundaySky videos help with conversion, they allow companies to upsell and retain customers through superior support materials. This way, synthetic voice creates immersive experiences that brings the custom video to life.
Video Avatars
Moving beyond video voiceover, Synthesia’s lifelike video avatars make digital learning material come to life. Whether used for training modules, customer support, or product marketing, the Synthesia avatars improve retention of information.
Custom video and video avatars are also taking the AI marketing space by storm. One Synthesia customer reported a 30% increase in engagement with e-learning materials for a training module. By using video avatars for training materials, others reported being able to reduce video creation time by 80%.
Inbound Call Centers, Customer Experience
Moving beyond video voiceover, Synthesia’s lifelike video avatars make digital learning material come to life. Whether used for training modules, customer support, or product marketing, the Synthesia avatars improve retention of information.
API vs. Studio Voice Content Creation
For those on the brink of integrating AI voice within apps or products, the conundrum often arises: should one begin with a studio service model or dive straight into the more versatile Text to Voice API? Each has its merits, but often the switch from studio to API proves fruitful.
Advantages of Leveraging an API
Smooth communication between software systems is more than a luxury—it’s a necessity. With solutions such as WellSaid Labs’ offering, manual data transfer hassles are a thing of the past. But that’s just the tip of the iceberg. Let’s examine how these APIs are reshaping business operations, from functionality to cost-efficiency.
Streamlined Integration: Voice APIs foster effortless communication among varied software systems. With an API like the one WellSaid Labs offers, the laborious manual data transfer is obsolete.
Enhanced Functionality: By tapping into functionalities like TTS API, businesses can readily metamorphose written content into authentic speech, circumventing the hurdles of traditional voiceover procurement.
Cost-efficiency Scalability: APIs sidestep the intricacies of creating new functions. Their flexibility lets businesses pay solely for the specific services they harness, ensuring they scale without draining resources.
Innovation & Collaboration: APIs are the vanguards of innovation, permitting businesses to construct upon pre-established platforms.
For those eyeing scalability, a TTS API, complemented with robust customer assistance and a history of reliability, is often the best bet.
AI Voice Implementation: The basics
Whether you aim to convert text-to-speech, recognize speech to transcribe it into text, or analyze voice patterns, the initial steps of implementation remain fairly consistent. This process begins with selecting a suitable API, understanding its documentation, setting up necessary authentication, and, crucially, understanding the costs associated with calls to the API.
API Selection: Before integrating, determine the specific needs of your application. Do you need multi-language support? Is real-time transcription a must? Once you’ve listed your requirements, evaluate available APIs based on accuracy, latency, scalability, and pricing.
Set-Up & Authentication: Most AI voice APIs require some form of authentication, commonly using API keys or OAuth tokens. After signing up, ensure that these keys are stored securely. Exposing them can lead to unauthorized use and associated costs.
Integration & Testing: Begin by making simple requests to the API, ensuring that your setup is correct. For voice recognition, start with a few test voice samples. For voice synthesis, experiment with different text inputs. It’s also crucial to handle different responses from the API, including potential errors.
Optimization: Depending on the response times and the volume of data being processed, you may need to make optimizations. This can include refining voice commands, tweaking voice prompts, or improving the handling of diverse accents and dialects.
Feedback Loops: Especially with voice recognition, feedback mechanisms can be invaluable. By allowing users to correct misinterpretations, you can gather data (with proper permissions) to improve and fine-tune the voice interaction experience.
Challenges and Overcoming Them
Every technological implementation comes with its set of challenges. With voice APIs, the common hurdles include dealing with noisy environments, understanding diverse accents, and managing the cost implications of high-volume API calls.
It’s essential to be proactive in addressing these challenges. Implementing noise-cancellation algorithms, providing training modules for the AI to better understand diverse user groups, and closely monitoring API usage to prevent unexpected costs are some measures that can be adopted.
Remember: The key to a successful AI voice API implementation is iterative refinement, ensuring that as the technology and user expectations evolve, your application continues to meet and exceed those expectations.
Integrations for AI Voice APIs
When we focus on AI voice technologies, APIs act as gateways, allowing developers to tap into powerful voice recognition, synthesis, and processing capabilities without having to build these complex systems from scratch. Integrating AI voice APIs into existing platforms, apps, or services can drastically enhance user experience, offer novel functionalities, and open doors to innovative use cases. From transcribing podcasts automatically to offering voice-based virtual assistants for e-commerce platforms, the possibilities are vast and varied.
Popular AI Voice API Integrations
Several key sectors have especially benefited from the integrations of AI voice APIs. In healthcare, voice recognition systems help doctors transcribe their notes in real-time, allowing for efficient patient care and reduced administrative burden. E-learning platforms employ voice synthesis to read out content for visually impaired students or to offer language translation for international learners.
Then, there are smart home devices, where integrations with voice APIs empower users to control their environments using simple voice commands. Furthermore, businesses employ voice bots for customer support, making use of AI voice APIs to interpret and respond to user queries. It’s important for developers to choose the right API that aligns with their specific needs, considering factors like language support, accuracy, latency, and cost.
Considerations and Best Practices
When integrating an AI voice API, it’s crucial to consider the user’s privacy and data security. As voice data can be sensitive, employing encryption and ensuring that data isn’t stored without permission becomes paramount.
Another key consideration is the user interface. Since voice interactions are fundamentally different from text or touch-based interactions, designing intuitive voice prompts and feedback systems is essential.
Lastly, while AI voice systems have come a long way in terms of accuracy, they aren’t infallible. Meaning, providing users with alternate means of interaction, especially in critical applications, ensures that the technology augments the user experience rather than hindering it. As AI voice technology continues to evolve, staying updated with the latest advancements and best practices will enable developers to create more seamless, effective, and user-friendly integrations.
Choosing the Right AI API
Finding the right API to suit your needs isn’t just about raw computational power. It’s also about ensuring a harmonious blend of accuracy, linguistic finesse, and top-notch security. Think of it as hiring an AI employee—you’d want one that communicates effectively, understands your audience, and safeguards sensitive information.
Accuracy & Naturalness: The gold standard of any text to speech AI API is its prowess in generating natural, articulate speech.
Language Proficiency: Opt for an API aligned with your target demographic’s language needs.Security & Compliance: Especially for applications that deal with delicate information, it’s pivotal to ensure your API choice is fortified against breaches.
Test Drive WellSaid API with Studio
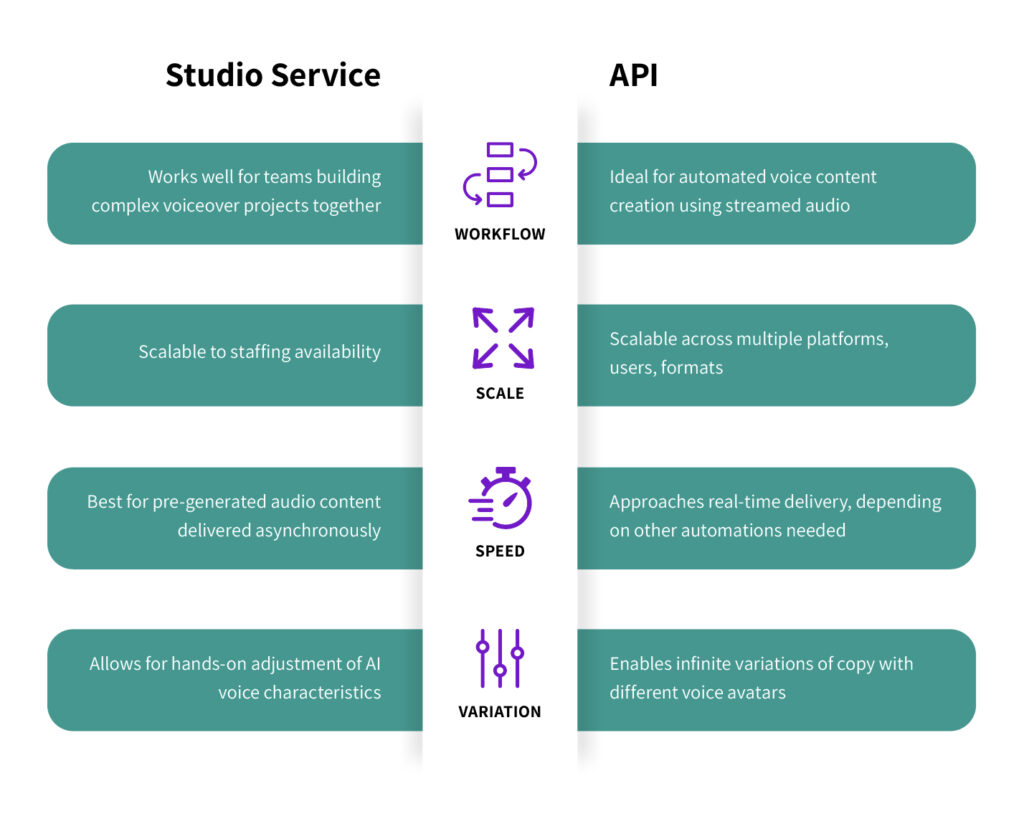
Depending on your voice goals, a manual “studio” creation method or a synthetic voice API will work best. In many cases, companies who want to integrate AI voice with apps or products will start with a Studio subscription. Clearly, this serves well for proof of concept before transitioning to a more robust API format. Here are some guidelines for which option may work best.
Studio Works Best When:
1. Works well for teams building complex voiceover projects together
2. Scalable to staffing availability
3. Best for pre-generated audio content delivered asynchronously
4. Allows for hands-on adjustment of AI voice characteristics
API Works Best When:
1. Ideal for automated voice content creation using streamed audio
2. Scalable across multiple platforms, users, formats
3. Approaches real-time delivery, depending on other automations needed
4. Enables infinite variations of copy with different voice avatars

3 Incredible Reasons to Use Voice Over API
How you can use a text-to-speech API
The potential for AI voice over APIs are endless. For example, you could use text-to-speech APIs to render a voice over version of every blog post you publish. The New York Times uses AI voice over APIs to translate children’s books into spoken versions. You could even use voice over APIs for mobile apps, learning and development content (e.g. voicing e-books aloud or translating to video versions), video game studios, voice assistant commands, and audio advertisements for podcasts, videos, and music streaming sites.
Why use an AI voice over API
When creating a voice over, you have a few options. You can upload a script to manually render each text-to-speech voice over, or you can use an API to automatically render a voice over when triggered by your system. There are a few benefits to the latter route.
One, using an API can simply be faster.
Instead of manually uploading scripts, an API can help automate the process for you. This delivers a voice over at certain trigger points in your projects workflows. For example, whenever you publish a blog post, you could have a text-to-speech API automatically render a voice over of the post. You multiply content by creating a complementary audio version. Not only does having an audio version look professional and potentially widen your audience, but through the power of the API, it doesn’t add any more work to your plate.
Second, a voice over API further defines your brand voice.
Everyone reads your articles in their own voice, bringing their own interpretation to your brand, but a voice over further colors and clarifies what your brand sounds like. If you construct a few voices that sound uniquely like your brand—or speak to a certain type of content or buyer persona—then an API can create a well-rounded set of voices across all of your brand assets.
Third, you only have to integrate an API once, and then the work is done.
From then on, unless paused, the API can automatically render voice overs for whatever parameters you set—when you publish blog posts, release podcast episodes, upload YouTube videos, and so on. The API integrates seamlessly with your system so you can become a voice over generating machine—no complex coding required.
Concluding Thoughts on Text-to-Speech APIs
There’s no denying it–digitization touches virtually every part of our lives. And with that, the nuances of human interaction and its recreation through technology become crucial. AI Voice APIs signify a deeper connection to our essence—bridging the gap between man and machine.
As we advance, let’s remember to reflect on how these innovations will influence our perception of reality, and the ethical implications that may come with it. A synthetic voice is absolutely a technological marvel. Nonetheless, it’s up to us to ensure it resonates with authenticity and serves a purpose beyond mere functionality. Meaning, it’s our collective responsibility to steer the course with intention and foresight.
Frequently Asked Questions
Finally, you may have more TTS questions. Here are some of the most common ones. If you don’t see your answer here, then please reach out to us.
How Much Does a Text-to-Speech API Cost?
Text-to-speech APIs are priced out based on usage, or the number of calls to the API. Basically, every provider from startups to a tech giant typically has tiered pricing based on usage. Most organizations anticipate text to speech API with dedicated support to cost several thousand dollars per year.
How Can I Save Money on TTS API Calls?
One of the ways to cut down on the cost of a voice generator API is to cache API recordings vs. always calling the API for a new text render.
Can WellSaid Build a Custom Voice Text-to-Speech API?
Yes, WellSaid Labs can build a custom voice into an API. Furthermore, AI Voice has elevated the capabilities of sonic branding. With WellSaid, your imagination can run wide. Take a look at the work we completed with Super Hi-Fi an alternative rock DJ AI Avatar.
What is a Voice Generator API vs. TTS API?
When people say voice generator api, or tts api they mean the same things. Since AI Voice is a developing technology the definitions people use varies. Text-to-voice, text-to-speech, voice maker, voice generator, or ai voice over are generally the same things.
What is a Text-to-Speech API?
Finally, a Text-to-Speech API is a tool that allows you to automatically convert text to speech, while also integrating additional functions of an application. On the other hand, a text-to-speech studio is a tool that does not require web development expertise. It allows anyone to copy and paste text, then download a voice rendering of the text, for example.