Audio by Ali P. using WellSaid Labs
Ever noticed the heartwarming flutter at the chirping of birds or the involuntary shiver from nails on a chalkboard? Sounds are more than auditory experiences. They’re deeply woven into our emotional tapestry.
With the meteoric rise of Text-To-Speech (TTS) software, the voices we invite into our lives have a profound effect on our psyche. From a booming $2.8 billion market in 2021 to a projected symphony of $12.5 billion by 2031, the landscape of auditory experiences is expanding.
And as the horizon broadens, understanding the psychological underpinnings of our voice choices becomes paramount. So, how do we hit the right note, every single time?
Let’s explore the labyrinth of voice psychology. And hear from a couple of our stellar voices along the way! 🗣️🗣️🗣️
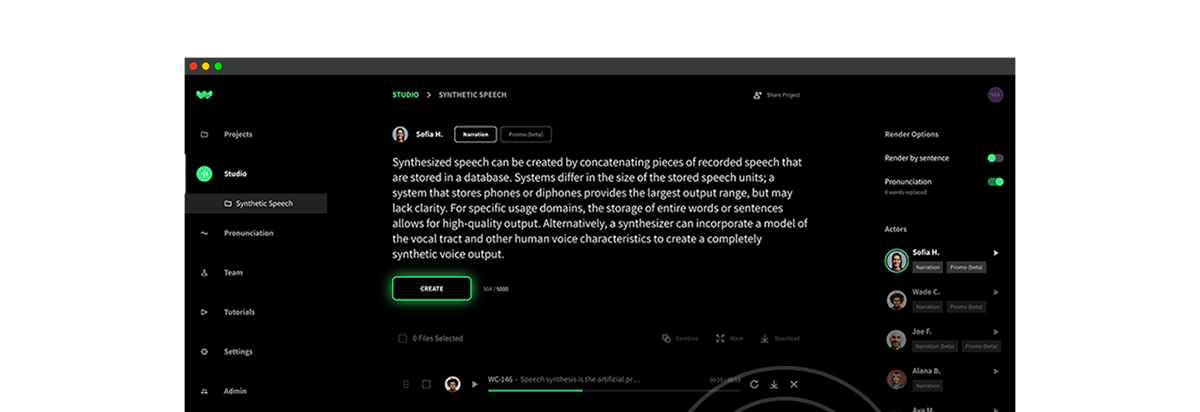
Learn more about using voice avatars here.
Hitting the low notes of leadership
A low, deep pitch often resonates with authority. In fact, research unveils a bias toward deeper, masculine tones for leaders, irrespective of gender. This isn’t a fleeting cultural fad. Rather, it’s a psychological inclination that exists despite the surrounding societal context.
It seems the allure of a deep voice isn’t just confined to leadership either. It’s tangled in the webs of attraction too. Biologically, deeper voices hint at higher testosterone levels, which often equates to perceptions of dominance and confidence.
But here’s the reality check: while deeper voices may create an impression of authority, their presence doesn’t guarantee the effectiveness of a leader. Such nuances of voice psychology invite us to be discerning and intentional in our voice choices.
What does that mean for voice producers like yourself? If you’d like your voice to command their audiences, opt for a deeper pitched one (like Michael below).
Voice by Michael V.
Echoes of self-love
Delving deeper, psychologists Hughes and Harrison unearthed a tantalizing revelation. We’re not just fond of our own voice–we’re smitten! This subtle narcissism is driven by a psychological phenomenon called selective attention. Basically that means that we’re wired to gravitate towards familiar, appealing stimuli.
How can we apply this to the context of TTS? Mirroring your audience’s demographics in your synthetic voice can be a strategic masterstroke. I.e. let them hear a familiar echo, and they’ll lean in
Voiced by Hannah A.
Voiced by Bella B.
The subtle art of uh and um
Contrary to popular belief, filler words aren’t your conversation’s junk food. They’re much more like seasoning. These “ums” and “uhs” serve as signals, guiding the listener, and highlighting what’s to follow. While overusing them in formal situations might be a no-no, a casual chat sans fillers can feel oddly robotic.
Herbert Clark, another psycholinguist, explains that while filler words may be discouraged in prepared speeches, their absence in casual conversations might drain the authenticity from the interaction.
The takeaway? If authenticity’s your game, let the fillers flow in moderation.
Voiced by James B.
Frying up perception
Vocal fry (that low, creaky vibration) has often been the signature style of many, especially among young, educated American women. But beware the sizzle as it might not always sell.
Studies warn that this trend, although intriguing, might be a credibility fryer. So it’s about balance. While clarity rules supreme in professional settings, that unsettling vocal fry might be perfect for a video game antagonist. Or, used in creative projects for an edgier narration.
Voiced by Charlie Z.
The chameleon of context
Voice modulation is anything but random. It’s actually a strategic choice rooted in psychology. Whether you’re casually chatting, reading aloud, or acting, your voice morphs. Different scenarios beckon different vocal nuances, intentional or not.
This voluntary modulation, from pitch to loudness, embeds non-verbal cues about the speaker’s intentions and emotions. For example, conversational speech is distinct from read speech, with differences occurring in the speech rate. Recognizing this, WellSaid Labs offers a voice smorgasbord of the big speaking styles—Promotional, Conversational, and Narration.
Voiced by Tilda C.
Discover more about AI voice for advertising and marketing here.
Tango with your tempo
Charisma often finds a companion in fast speech. After all, a rapid-fire delivery exudes confidence and mastery. But, voice psychology cautions us against getting swept away. Talking too rapidly can cloud comprehension, leaving listeners adrift. The solution? Deliberate modulation. By seamlessly oscillating between speeds, we can craft a rhythm that engages and captivates.
Voiced by Fiona H.
Concluding thoughts on voice psychology
From the deep tones that command authority to the often frowned-upon filler words that add authenticity, the sounds we choose and hear shape our interactions. As the realm of TTS advances, the tools to fine-tune our voices become ever more sophisticated. The right voice can make your message not just heard, but felt. And as TTS technology evolves, the possibilities for personalized, psychologically-attuned voices are boundless.
Eager to find your perfect pitch? Jump in with WellSaid Labs, and let’s craft transformative audio experiences.