Crafting authentic vocal performances via interpolable in-context cues
Audio by Paige L. using WellSaid Labs
This post is from the WellSaid Research team, exploring breakthroughs and thought leadership within audio foundation model technology.
Today, we announce a breakthrough in generative modeling for speech synthesis: HINTS (or Highly Intuitive Naturally Tailored Speech). This work from the WellSaid Labs team introduces a novel generative model architecture combining state-of-the-art neural text-to-speech (TTS) with contextual annotations to enable a new level of artistic direction of synthetic voice outputs.
Why is controlling generative models difficult?
In recent years, generative models have ushered in a paradigm shift in content production. And yet, despite their transformative capabilities, ensuring these models answer to users’ specific creative preferences remains challenging. Currently, the prevailing method for solving this challenge and controlling generative models is by using natural language descriptions (i.e., prompts). However, many artistic preferences are nuanced and difficult to capture within a single prompt. Content creators often need to learn how to write good prompts to interact more effectively with AI and get their desired results.
For TTS in particular, the intricacies of speech (tone, pitch, rhythm, pronunciation preferences, intonation) add additional layers of complexity. While not a modeling approach, SSML has allowed veteran TTS users one mechanism by which they can make precise voice modification requests. However, more artistic modifications such as pitch and rhythm are often coarse and can only be applied to entire sentences. Consequently, the results often sound unnatural.
How does HINTS work?
HINTS is a new model architecture based on the approach introduced in StyleGAN. StyleGAN and its related models decouple the latent spaces, enabling precise manipulations that range from high-level attributes to finer details. These controls are not only precise and interpolable – the mechanisms by which they operate are understandable and replicable.
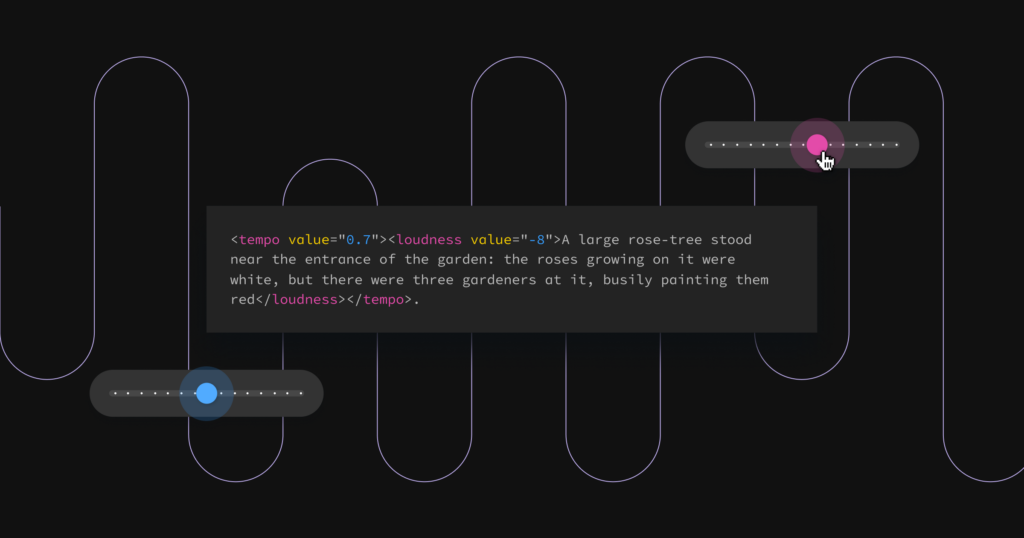
Following a similar approach, our flagship TTS model learns a mapping network that maps from contextual annotations (cues) to a latent space 𝒲 that controls the generator. This architecture allows users to generate high-quality, diverse, natural voice performances of the same script and speaker through a mechanism aware of the surrounding context.
Initially, we released loudness and tempo cues, addressing their historical challenges using this framework. Where loudness controls traditionally vary decibel outputs, as is the case with SSML tagging, our loudness cue allows for a range of performances that vary in timbre, which is important for natural prosody. Similarly, our tempo cue does not modify pitch, addressing the complex inverse relationship between frequency and time.
What does HINTS do that’s different?
HINTS addresses gaps in current approaches by enabling users to guide the model toward specific deliveries through various cues. HINTS introduces a way for users to hear a first “basic” take of their text and then make finely-tuned adjustments to subsequent takes. Moreover, the model interprets these adjustments on every iteration, allowing for far more natural-sounding results.
WellSaid’s annotations, whether they’re used individually or nested, allow for an expansive range of realistically synthesized expressive and performative audio.
Rhyan Johnson, Machine Learning Product Manager
HINTS is able to take direction and interpret it with precise scalability, responding effectively to minor incremental adjustments. In other words, user inputs can be granular, where a Loudness 4 performance will, in fact, show an increase in LUFS than a Loudness 3 performance. Not only can multiple cues be used in a single clip, they also work when combined (nested within one another) and over long ranges of text (stability up to 5,000 characters).
All of these capabilities combined make HINTS a significant breakthrough not only for speech synthesis but also within the field of generative modeling.
Learn more
Read our paper and listen to our comprehensive audio samples here, or sign up for a trial at wellsaidlabs.com to try a beta model built on the HINTS architecture.
Selected samples
To evaluate the impact of annotations on speech output, we listened to hundreds of audio samples created from text with tempo and loudness annotations applied at varying levels. We selected a few of our favorite samples here. For a more comprehensive collection of audio samples illustrating additional model capabilities, please view our paper.
In these first four examples, we show this release’s primary technical accomplishment: Our solution allows users to guide the model toward specific deliveries by using loudness and tempo annotations.
We show how Ben D., one of our South African voices, reads the following eLearning script in his narration style, both uncued and with direction:
Script: Time for a quick Knowledge Check! Please read the questions carefully before selecting your answers.
Clip 1
No annotations; this is Ben’s natural read in his narration style.
Clip 2
We added a slow tempo cue to the call to action, “read the questions carefully.” A user may choose this audio clip if these instructions differ from previous sections, or if this is the first time they’ve asked their students to perform this activity.
Clip 3
We added a slow-tempo cue and a loud cue to the activity name, “Knowledge Check.” A user may choose this audio clip to reinforce that this is a new section.
Clip 4
This example combines some of the above approaches and shows how a single short passage can include a loudness cue (Knowledge Check), a tempo cue (read the questions carefully), and a nested cue (before).
For text whose meaning depends greatly on the tone of voice (“You’re so funny” or “It’s not a big deal”), annotations can point the model toward a host of different affective effects.
We show this capability with Jordan T., a US English voice, whose narration voice illustrates three different takes on the same text.
Script: I didn’t say you were wrong.
Clip 5
No annotations; this is Jordan’s natural read in her narration style.
Clip 6
A faster, louder version creates a casual, offhand delivery.
Clip 7
A slower, quieter version creates a measured, controlled delivery.
Annotations can also be applied to punctuation marks so that pauses can be increased without interfering with the sentence’s prosody. This sample shows how pauses added to ellipses increased the drama for this incredibly silly, very much made-up movie trailer. This sample is read by Joe F., US English, in his promo style:
Script: In a town… with only one sheriff… and three tons of banana peels… who will win… and who will slip…
Clip 8
Annotations applied to ellipses, and final phrase made quieter and slower to heighten intrigue.