
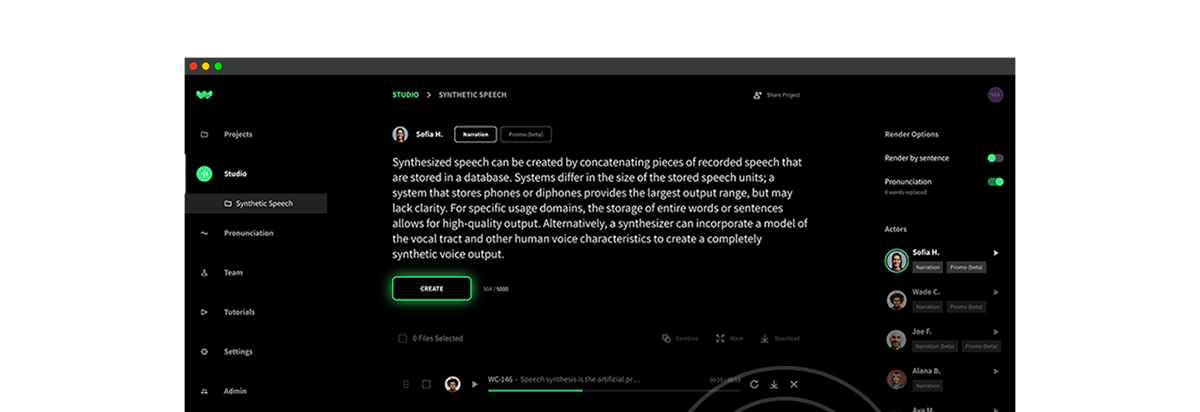
Audio by Tilda C. using WellSaid Labs This post is from the WellSaid Research team, exploring breakthroughs and thought leadership within audio foundation model technology. The prospect of machines mimicking
© WellSaid, Inc. 2024
All rights reserved.
