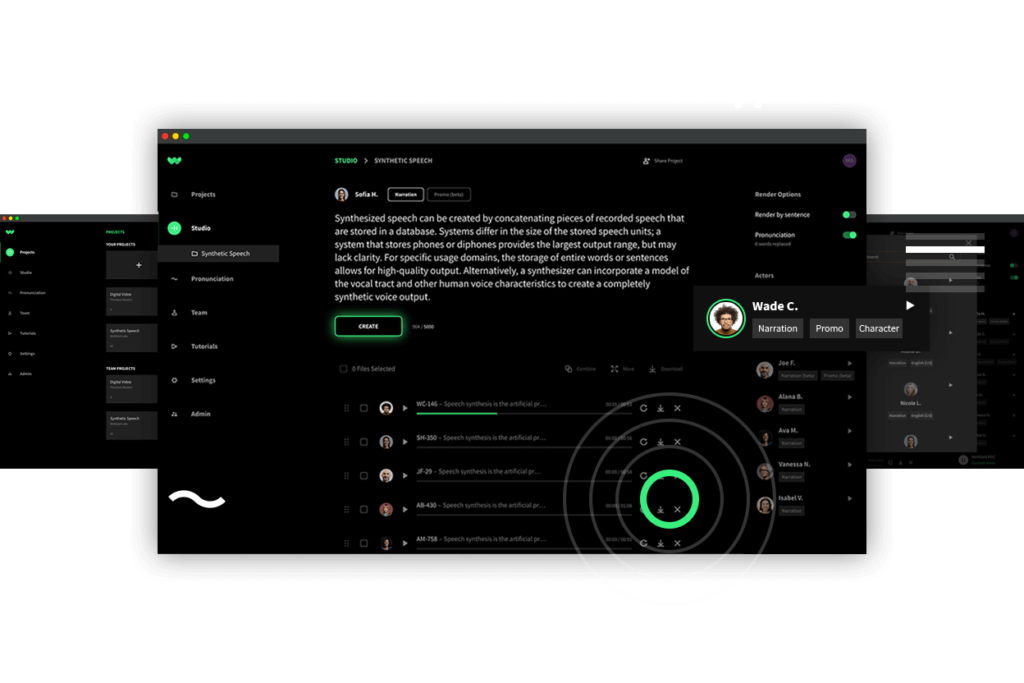
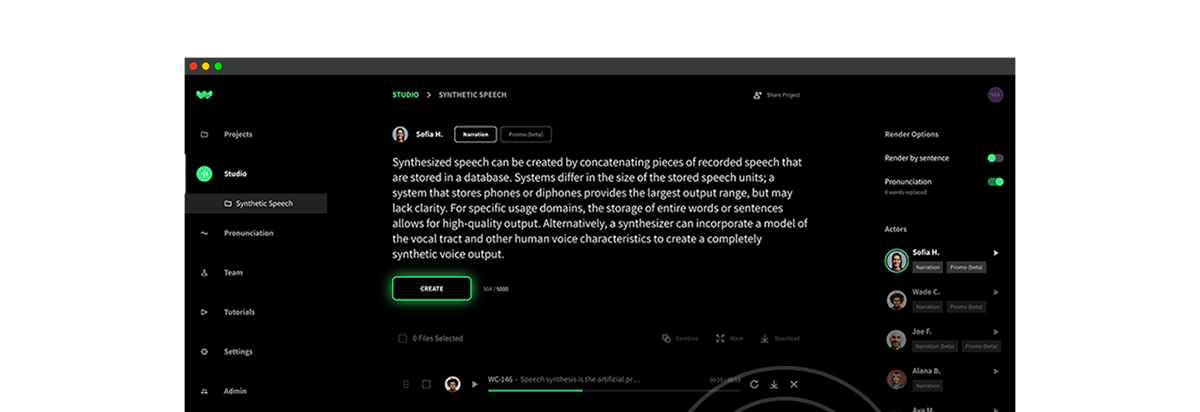
Collaboration made easy
Bring everyone in your team together to tell a unified story — with one AI voice or many.
Collaboration made easy
Bring everyone in your team together to tell a unified story — with one AI voice or many.
Collaboration made easy
Bring everyone in your team together to tell a unified story — with one AI voice or many.